DataOps: "Data Sources" Deep Dive
Pillar 1: Data Sources – The Foundation of AI-Ready Data
In our first post on DataOps, we explored how AI’s success hinges not just on powerful models, but on the quality, accessibility, and governance of the data that fuels them. And it all starts at the source.
This blog dives into Pillar 1: Data Sources—the critical first layer of your DataOps pipeline. We'll cover everything you need to build a strong data foundation:
- What counts as a data source: From operational databases and unstructured file stores to real-time streams, IoT platforms, SaaS applications, and external APIs.
- Why high-quality inputs matter: Understand how data fragmentation, manual entry, and lack of synchronization create blind spots that undermine analytics and AI.
- How to build a Controlled Ingest Layer: Learn how to define, govern, secure, and validate raw data before it flows downstream—ensuring trust and usability from the start.
- A readiness checklist and real-world use case: Get actionable guidance to assess your current data landscape and avoid common pitfalls.
- Tools & Platforms Directory: Explore a categorized list of 100+ tools used across industries to manage, catalog, and validate data sources—so you can choose what fits your stack.
As a quick refresher, our previous post outlined the 5 Pillars of DataOps, which include:
- Data Sources – Where raw data originates (transactional DBs, file stores, external APIs).
- Data Ingestion & Integration – Unifying data through batch, real-time, and streaming pipelines.
- Data Storage & Management – Warehousing the data in lakes, lakehouses, or other high-performance systems.
- Data Processing & Governance – Ensuring quality, lineage, and compliance of the data.
- Data Orchestration & AI Consumption – Delivering continuous insights through AI/ML models and BI tools.
This post dives deep into Pillar 1, setting the stage for a robust DataOps pipeline by focusing on the raw data coming from various sources and ensuring it’s ready for transformation into actionable intelligence.
Why Pillar 1 (Data Sources) Matters
AI systems and BI platforms are only as good as the data they ingest. However, this data is fragmented, inconsistent, or incomplete right from the source. Common challenges include:
- Siloed Systems: Multiple departments or tools managing similar data independently.
- Manual Data Entry: Human errors and duplicate records that creep in during manual input.
- Lack of Synchronization: Systems that don’t communicate in real time, resulting in outdated or mismatched information.
- Neglected Unstructured Data: Important inputs like logs, images, audio, and documents left outside analytics pipelines.
- Poor Visibility: A lack of metadata, ownership, and clear lineage that obscures the true state of data.
The consequences? Misinformed decisions, eroded customer trust, wasted resources, and AI models that fail to deliver when it matters most.
Scope of Pillar 1: What Counts as a Data Source?
Pillar 1 is solely about the origins of raw data—the systems that generate or store it—not about how it's moved, transformed, or stored (that’s handled in Pillars 2 and 3).
Data Sources can be structured, semi-structured, or unstructured, and span across internal systems, third-party platforms, and real-time external feeds.
🔹Operational Databases (Relational & NoSQL)
These systems store transactional, customer, or business data in structured formats:
- Relational DBs: PostgreSQL, MySQL, SQL Server, Oracle, MariaDB, IBM Db2, SAP HANA, Amazon Aurora
- NoSQL DBs: MongoDB, DynamoDB, Cassandra, Couchbase, Firestore
Also includes:
- Cloud-native databases: Google Cloud SQL, Azure SQL Database
- Analytical engines used as sources: Vertica, Greenplum, ClickHouse, Snowflake, Databricks
🔹 Real-Time / Streaming Systems
Systems that generate continuous event data or telemetry:
- Stream Processing: Apache Kafka, Pulsar, Flink, Storm
- Cloud-native: AWS Kinesis, Google Pub/Sub, Azure Event Hubs
- Managed platforms: Confluent, Redpanda, StreamSets, Quix, Benthos
- Often includes Databricks Structured Streaming as a source for real-time insights
🔹 IoT & Sensor Data Platforms
These platforms produce telemetry and device-generated data:
- Platforms: AWS IoT Core, Azure IoT Hub, Google Cloud IoT
- Edge or embedded tools: Kaa, ThingSpeak, Losant, HiveMQ, Particle
🔹 File-Based & Unstructured Repositories
Repositories where large volumes of semi-structured or unstructured data are stored:
- Cloud object stores: Amazon S3, Azure Blob Storage, Google Cloud Storage, MinIO, Wasabi
- File services: Dropbox, Box, SharePoint, Backblaze, Internal file shares
- Also includes structured file lakes like Delta Lake (Databricks) and Snowflake External Stages
🔹 Logs, Text & Search Indexes
Machine-generated or log-based sources often used for real-time or historical analysis:
- Search/index tools: Elasticsearch, OpenSearch
- Logging platforms: Splunk, Graylog, Logstash, Fluentd, Vector, Papertrail, Sumo Logic, Datadog Logs
🔹 SaaS & Business Applications
SaaS platforms that store critical business, sales, and customer engagement data:
- CRM & ERP: Salesforce, HubSpot, Workday, NetSuite, SAP, Oracle Cloud Apps
- Support & ITSM: Zendesk, ServiceNow, Jira
- Marketing: Marketo, Pardot, Gainsight
- Productivity: Asana, Smartsheet, Monday.com
- Snowflake Marketplace and Databricks Partner Connect also act as live SaaS-connected data feeds
🔹 External APIs & Public Data Feeds
Real-time or batch feeds from external providers or data aggregators:
- Financial & market: Alpha Vantage, Quandl, IEX Cloud
- Weather & geospatial: OpenWeather, WeatherAPI
- Social & digital: Twitter API, Reddit API, Facebook Graph API, Google Analytics
- Government & public sector: World Bank Data, US Census API, NYC Open Data, AWS Data Exchange
🔹 Open Data Sets & Partner Exchanges
Pre-published or shared data sources used for benchmarking or enrichment:
- Aggregators: Kaggle Datasets, Google Dataset Search, UCI ML Repository
- Public portals: Data.gov, EU Open Data Portal, UN Data, AWS Open Data
At this stage, it’s not just about connecting to these sources—it’s about understanding:
- What data is coming in
- Where it originates
- Who owns it
- How frequently it updates
- Whether it’s fit for purpose
This is the foundation of trust and usability that everything else in your DataOps pipeline is built on.
From Raw Data to Trusted Data: The Controlled Ingest Layer
To ensure that raw inputs become AI-ready, we embed them within a Controlled Ingest Layer. The diagram below illustrates how data sources feed into this layer, establishing a robust foundation for all downstream processes.
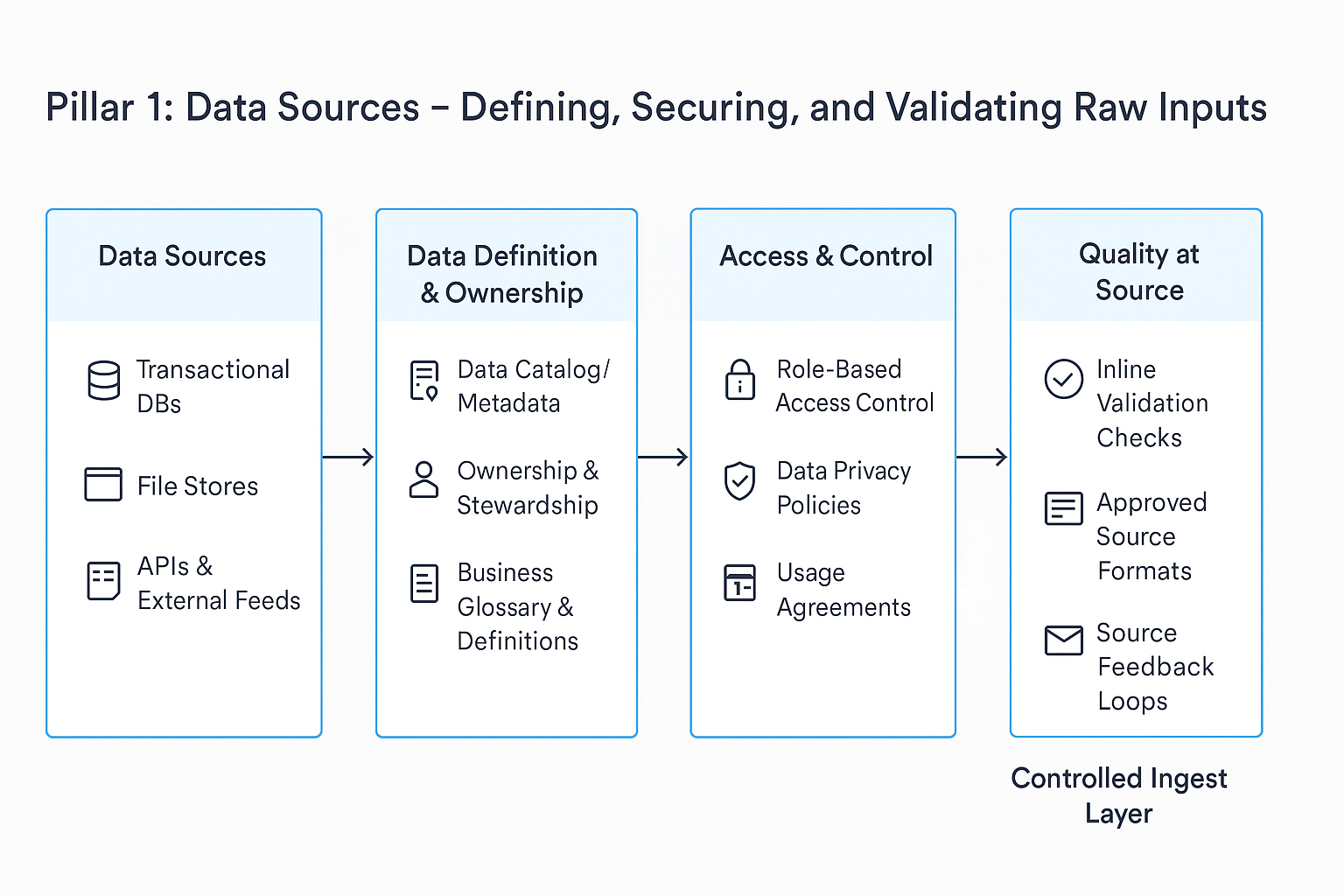
What This Diagram Represents
This diagram outlines the critical components required to transform raw inputs into trusted, high-quality data ready for AI, analytics, and automation. By addressing definition, ownership, access, and validation at the source, the framework prevents downstream issues such as poor analytics, inaccurate models, and compliance failures.
- Data Sources:
The very origins of your data, as listed above—transactional systems, file repositories, APIs, and external feeds. The goal is not merely to connect but to understand the nature and purpose of every piece of data. - Data Definition & Ownership:
Once you identify your sources, it’s vital to document metadata, assign clear ownership, and create a business glossary. This ensures every dataset is well understood and that similar fields (like “customer ID” or “transaction type”) are standardized across the organization. - Access & Control:
Not all data should be universally accessible. Here, robust mechanisms such as role-based access control, data privacy policies, and usage agreements protect sensitive data and ensure that only the right people have access. - Quality at Source:
Inline validation checks, approved source formats, and source feedback loops work together to catch errors—such as missing fields, schema drift, or misformatted data—early, thus preserving the integrity of your entire data pipeline.
Together, these layers create a trusted data foundation that is well-defined, secure, owned, and validated. Only when these conditions are met should data proceed to ingestion, integration, storage, and AI consumption (covered in Pillars 2 through 5).
Use Case Scenario: Fragmented Data in Disconnected Systems
Scenario:
Imagine a multi-location enterprise—whether in retail, healthcare, logistics, or manufacturing—that manages customer or asset records using an ERP, a POS system, a web platform, and an internal reporting tool. Although each system was deployed for specific business needs, over time they have led to redundant and conflicting data.
Symptoms:
- Duplicate Entries: The same customer, supplier, or asset appears multiple times across systems.
- Conflicting Details: Records vary in spelling, location, or metadata, causing ambiguity.
- Inaccurate Forecasting: Inconsistent data inputs lead to poor predictions and unreliable AI models.
- Manual Reconciliation: Teams spend valuable time manually merging and cleaning data, delaying decision-making.
DataOps Solution:
To tackle these challenges, a comprehensive DataOps strategy is implemented at the data source level:
- Data Integration:
- Connect Systems: Seamlessly integrate the ERP, POS, web platform, and reporting tools into a unified data repository.
- Automated Pipelines: Use ETL/ELT tools or real-time streaming solutions to consolidate data efficiently, ensuring that updates from one system are reflected across all.
2. Data Deduplication:
- AI-Driven Matching: Apply rule-based and AI-driven deduplication algorithms to identify and merge redundant records into a single master record.
- Master Data Management (MDM): Establish a centralized “master” record for each customer or asset, ensuring consistent and clear data across systems.
3. Data Governance:
- Standardized Definitions: Implement a data catalog and business glossary to standardize field names and definitions, reducing ambiguity (e.g., “customer ID” or “asset number”).
- Clear Ownership: Assign clear data ownership and stewardship for each system to enforce consistency and accountability.
4. Real-Time Synchronization:
- Immediate Updates: Enable near real-time updates so that any change in one system is automatically propagated to all others, minimizing discrepancies.
5. Data Quality Monitoring:
- Continuous Validation: Implement inline validation checks at the source to catch missing fields, formatting errors, or schema drift as data is ingested.
- Feedback Loops: Establish communication channels where downstream users (analysts, AI teams) provide immediate feedback to data owners for rapid resolution of quality issues.
Data Sources Readiness Checklist
This checklist helps you assess whether your organization is truly ready at the data source level. If these foundational elements aren’t in place, downstream issues will almost always follow.
✅ Mapped Data-Producing Systems: Have you documented every system that generates or stores data?
✅ Defined Data Ownership: Are the data definitions and responsible owners clearly assigned?
✅ Captured and Updated Metadata: Is detailed metadata stored centrally?
✅ Enforced Standard Formats: Are standard data formats and schemas applied at the source?
✅ Secured Sensitive Data: Are proper access policies in place to protect sensitive information?
✅ Early Quality Checks: Are duplicate records and quality issues caught at the source rather than after ingestion?
✅ Monitored Data Freshness & Update Frequency: Is each data source delivering updates on time and in sync with operational needs?
✅ Aligned Data Sources with Business Use Cases: Are critical data sources mapped to strategic AI and analytics initiatives?
Tools & Platforms for Pillar 1: Data Sources
Below is a curated list of tools and platforms across every major category in the DataOps Pillar 1 landscape. These solutions help organizations identify, connect to, catalog, and validate data sources before ingestion.
🔹 Operational Databases (Relational & NoSQL)
PostgreSQL, MySQL, MariaDB, Oracle, SQL Server, IBM Db2, SAP HANA, MongoDB, Cassandra, Couchbase, DynamoDB, Firestore, Amazon Aurora, Google Cloud SQL, Azure SQL Database, ClickHouse, Greenplum, Vertica, Snowflake, Databricks
🔹 Real-Time / Streaming Systems
Apache Kafka, Apache Pulsar, Apache Flink, Apache Storm, AWS Kinesis, Google Pub/Sub, Azure Event Hubs, Redpanda, Confluent, StreamSets, Quix, Benthos, Databricks Structured Streaming
🔹 IoT & Sensor Data Platforms
Azure IoT Hub, AWS IoT Core, Google Cloud IoT, Kaa IoT Platform, ThingSpeak, Losant, Particle, HiveMQ
🔹 File-Based & Unstructured Repositories
Amazon S3, Azure Blob Storage, Google Cloud Storage, MinIO, Wasabi, Backblaze B2, Box, Dropbox, SharePoint, Network File Shares, Snowflake External Stages, Databricks Delta Lake
🔹 Logs, Text & Search Indexes
Elasticsearch, OpenSearch, Splunk, Graylog, Logstash, Fluentd, Vector, Papertrail, Sumo Logic, Datadog Logs
🔹 SaaS & Business Applications
Salesforce, HubSpot, Zendesk, Workday, ServiceNow, SAP, NetSuite, Oracle Cloud Apps, Marketo, Pardot, Gainsight, Jira, Asana, Snowflake Marketplace, Databricks Partner Connect
🔹 External APIs & Public Data Feeds
Alpha Vantage, Quandl, WeatherAPI, OpenWeather, Twitter API, Reddit API, Google Analytics, Facebook Graph API, World Bank Data, US Census API, AWS Data Exchange, NYC Open Data
🔹 Open Data Sets & Partner Exchanges
Kaggle Datasets, Google Dataset Search, UCI Machine Learning Repository, AWS Open Data, EU Open Data Portal, UN Data, Data.gov
🔹 Metadata Management & Data Catalogs (for Source Governance & Visibility)
Alation, Collibra, Atlan, Data.World, Amundsen, Apache Atlas, Microsoft Purview, Google Data Catalog, Informatica EDC, Databricks Unity Catalog
| Category | Tool/Platform | URL |
|---|---|---|
| Operational Databases (Relational & NoSQL) | PostgreSQL | https://www.postgresql.org/ |
| Operational Databases (Relational & NoSQL) | MySQL | https://www.mysql.com/ |
| Operational Databases (Relational & NoSQL) | MariaDB | https://mariadb.org/ |
| Operational Databases (Relational & NoSQL) | Oracle | https://www.oracle.com/database/ |
| Operational Databases (Relational & NoSQL) | SQL Server | https://www.microsoft.com/en-us/sql-server |
| Operational Databases (Relational & NoSQL) | IBM Db2 | https://www.ibm.com/products/db2-database |
| Operational Databases (Relational & NoSQL) | SAP HANA | https://www.sap.com/products/technology-platform/hana.html |
| Operational Databases (Relational & NoSQL) | MongoDB | https://www.mongodb.com/ |
| Operational Databases (Relational & NoSQL) | Cassandra | https://cassandra.apache.org/ |
| Operational Databases (Relational & NoSQL) | Couchbase | https://www.couchbase.com/ |
| Operational Databases (Relational & NoSQL) | DynamoDB | https://aws.amazon.com/dynamodb/ |
| Operational Databases (Relational & NoSQL) | Firestore | https://firebase.google.com/products/firestore |
| Operational Databases (Relational & NoSQL) | Amazon Aurora | https://aws.amazon.com/rds/aurora/ |
| Operational Databases (Relational & NoSQL) | Google Cloud SQL | https://cloud.google.com/sql |
| Operational Databases (Relational & NoSQL) | Azure SQL Database | https://azure.microsoft.com/en-us/products/azure-sql/ |
| Operational Databases (Relational & NoSQL) | ClickHouse | https://clickhouse.com/ |
| Operational Databases (Relational & NoSQL) | Greenplum | https://greenplum.org/ |
| Operational Databases (Relational & NoSQL) | Vertica | https://www.vertica.com/ |
| Operational Databases (Relational & NoSQL) | Snowflake | https://www.snowflake.com/ |
| Operational Databases (Relational & NoSQL) | Databricks | https://www.databricks.com/ |
| Real-Time / Streaming Systems | Apache Kafka | https://kafka.apache.org/ |
| Real-Time / Streaming Systems | Apache Pulsar | https://pulsar.apache.org/ |
| Real-Time / Streaming Systems | Apache Flink | https://flink.apache.org/ |
| Real-Time / Streaming Systems | Apache Storm | https://storm.apache.org/ |
| Real-Time / Streaming Systems | AWS Kinesis | https://aws.amazon.com/kinesis/ |
| Real-Time / Streaming Systems | Google Pub/Sub | https://cloud.google.com/pubsub |
| Real-Time / Streaming Systems | Azure Event Hubs | https://azure.microsoft.com/en-us/products/event-hubs/ |
| Real-Time / Streaming Systems | Redpanda | https://redpanda.com/ |
| Real-Time / Streaming Systems | Confluent | https://www.confluent.io/ |
The Bottom Line: Start Strong, Scale Smarter
Getting your data sources right isn’t just a technical task—it’s a strategic advantage. When you treat raw data as an asset instead of an afterthought, everything downstream becomes faster, smarter, and more reliable.
With the right foundations in place—clear ownership, well-defined formats, trusted systems, and continuous validation—you unlock the full potential of AI, analytics, and automation. And as the DataOps journey continues through ingestion, storage, processing, and orchestration, you'll already be ahead of the curve.
Pillar 1 sets the tone. Get it right, and every other pillar becomes easier to scale, govern, and optimize.
Now that your sources are ready, stay tuned as we dive into Pillar 2: Data Ingestion & Integration—where we’ll explore how to seamlessly bring this data into your ecosystem, in real time and at scale.














ITOpsAI Hub
A living library of AI insights, frameworks, and case studies curated to spotlight what’s working, what’s evolving, and how to lead through it.

What you’ll find in AI Blogs & Insights:
- Practical guides on AIOps, orchestration, and AI implementation
- Use case breakdowns, frameworks, and tool comparisons
- Deep dives on how AI impacts IT strategy and operations

What You'll Find in Resources:
- Curated reports, research, and strategic frameworks from top AI sources
- Execution guides on governance, infrastructure, and data strategy
- Trusted insights to help you scale AI with clarity and confidence

What You'll Find in Case Studies:
- Vetted examples of how companies are using AI to automate and scale
- Measurable outcomes from infrastructure, IT, and business transformation
- Strategic insights on execution, orchestration, and enterprise adoption